A. Beck and M. Teboulle, "A fast iterative shrinkage-thresholding algorithm for linear inverse problems", SIAM Journal on Imaging Sciences,
vol. 2, no. 1, pp. 183–202, 2009. View the paper.
If you find any issue, please let me know via this. I would really appreciate. Thank you.
Note: Results in this repo are compared with those obtained by the SPAMS toolbox. You need to install spams and put the generated 'build' folder under the 'spams' folder of this repo.
g: R^n -> R: a continuous convex function which is possibly nonsmooth.
f: R^n -> R: a smooth convex function of the type C^{1, 1}, i.e., continuously differentiable with Lipschitz continuous gradient L(f):
||grad_f(x) - grad_f(y)|| <= L(f)||x - y|| for every x, y \in R^n
Note: this implementation also work on nonnegativity constrained problems.
Algorithms
If L(f) is easy to calculate,
We use the following algorithm:
where pL(y) is a proximal function defined as:
For a new problem, our job is to implement two functions: grad_f(x) and pL(y) which are often simpler than the original optimization stated in (1).
INPUT:grad:afunctioncalculatinggradientoff(X) givenX.
proj:afunctioncalculatingpL(x) -- projectionXinit:amatrix -- initialguess.
L:ascalartheLipschitzconstantofthegradientoff(X).
opts:astructopts.lambda:aregularizationparameter, canbe either a scalar oraweighted matrix.opts.max_iter:maximumiterationsofthealgorithm.
Default300.opts.tol:atolerance, thealgorithm will stop if difference betweentwo successive X is smaller than this value. Default1e-8.opts.verbose:showingF(X) aftereachiterationornot.
Defaultfalse. calc_F:optional, afunction calculating value of F at X viafeval(calc_F, X). OUTPUT:X:solutioniter:numberofruniterationsmin_cost:theachievedcost
fista_backtracking
function X = fista_backtracking(calc_f, grad, Xinit, opts, calc_F)
INPUT:calc_f:afunctioncalculatingf(x) inF(x) =f(x) +g(x)
grad:afunctioncalculatinggradientoff(X) givenX.
Xinit:amatrix -- initialguess.
opts:astructopts.lambda:aregularizationparameter, canbe either a scalar oraweighted matrix.opts.max_iter:maximumiterationsofthealgorithm.
Default300.opts.tol:atolerance, thealgorithm will stop if difference betweentwo successive X is smaller than this value. Default1e-8.opts.verbose:showingF(X) aftereachiterationornot.
Defaultfalse. opts.L0:apositivescalar.
opts.eta: (mustbe>1). etainthealgorithm (page194)
calc_F:optional, afunction calculating value of F at X viafeval(calc_F, X). OUTPUT:X:solution
Examples
Lasso (and weighted) problems
Optimization problem:
This function solves the l1 Lasso problem:
if lambda is a scalar, or :
if lambda is a matrix. In case lambda is a vector, it will be converted to a matrix with same columns and its # of columns = # of columns of X.
A toy example:
Data dimension : 300
No. of samples : 70
No. of atoms in the dictionary: 100
=====================================================
Lasso FISTA solution vs SPAMS solution,
both of the following values should be close to 0.
1. average(norm1(X_fista - X_spams)) = 0.000028
2. costfista - cost_spams = 0.000003
SPAMS provides a better cost.
=====================================================
Lasso Weighted FISTA solution vs SPAMS solution,
both of the following values should be close to 0.
1. average(norm1(X_fista - X_spams)) = 0.000015
2. costfista - cost_spams = -0.000004
FISTA provides a better cost.
================Positive Constraint===================
Lasso FISTA solution vs SPAMS solution,
both of the following values should be close to 0.
1. average(norm1(X_fista - X_spams)) = 0.000025
2. costfista - cost_spams = 0.003537
SPAMS provides a better cost.
================Positive Constraint===================
Lasso Weighted FISTA solution vs SPAMS solution,
both of the following values should be close to 0.
1. average(norm1(X_fista - X_spams)) = 0.000016
2. costfista - cost_spams = -0.000005
FISTA provides a better cost.
Elastic net problems
Optimization problem:
This function solves the Elastic Net problem:
if lambda is a scalar, or :
if lambda is a matrix. In case lambda is a vector, it will be convert to a matrix with same columns and its # of columns = # of columns of X.
functiontest_row_sparsity()
clc
d =30; % data dimension
N =70; % number of samples
k =50; % dictionary size
lambda =0.01;
Y =normc(rand(d, N));
D =normc(rand(d, k));
%%cost function functionc=calc_F(X)
c =0.5*normF2(Y-D*X) +lambda*norm12(X);
end%%fista solution
opts.pos =true;
opts.lambda =lambda;
opts.check_grad =0;
X_fista =fista_row_sparsity(Y, D, [], opts);
cost_fista =calc_F(X_fista);
fprintf('cost_fista = %.5s\n', cost_fista);
end

 客服电话
客服电话
 APP下载
APP下载

 官方微信
官方微信







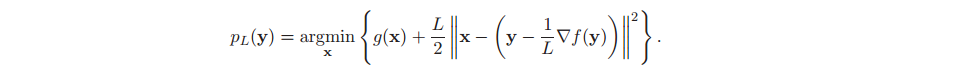

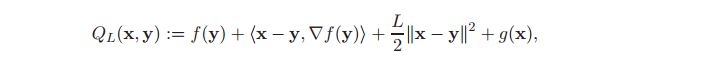


















请发表评论