开源软件名称:kingname/JsonPathFinder
开源软件地址:https://github.com/kingname/JsonPathFinder
开源编程语言:
Python
100.0%
开源软件介绍:如何快速从深层嵌套 JSON 中找到特定的 Key
#公众号
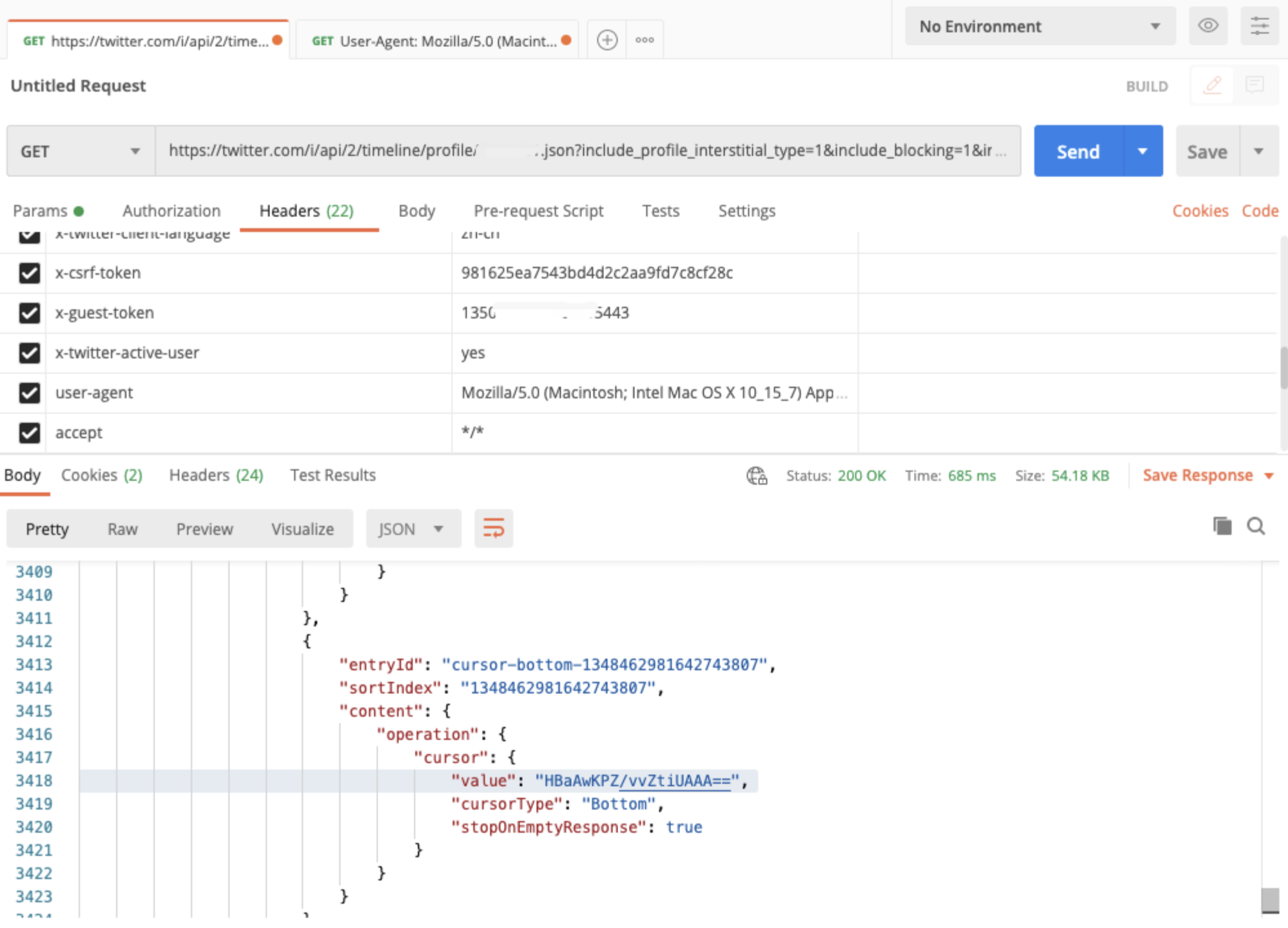
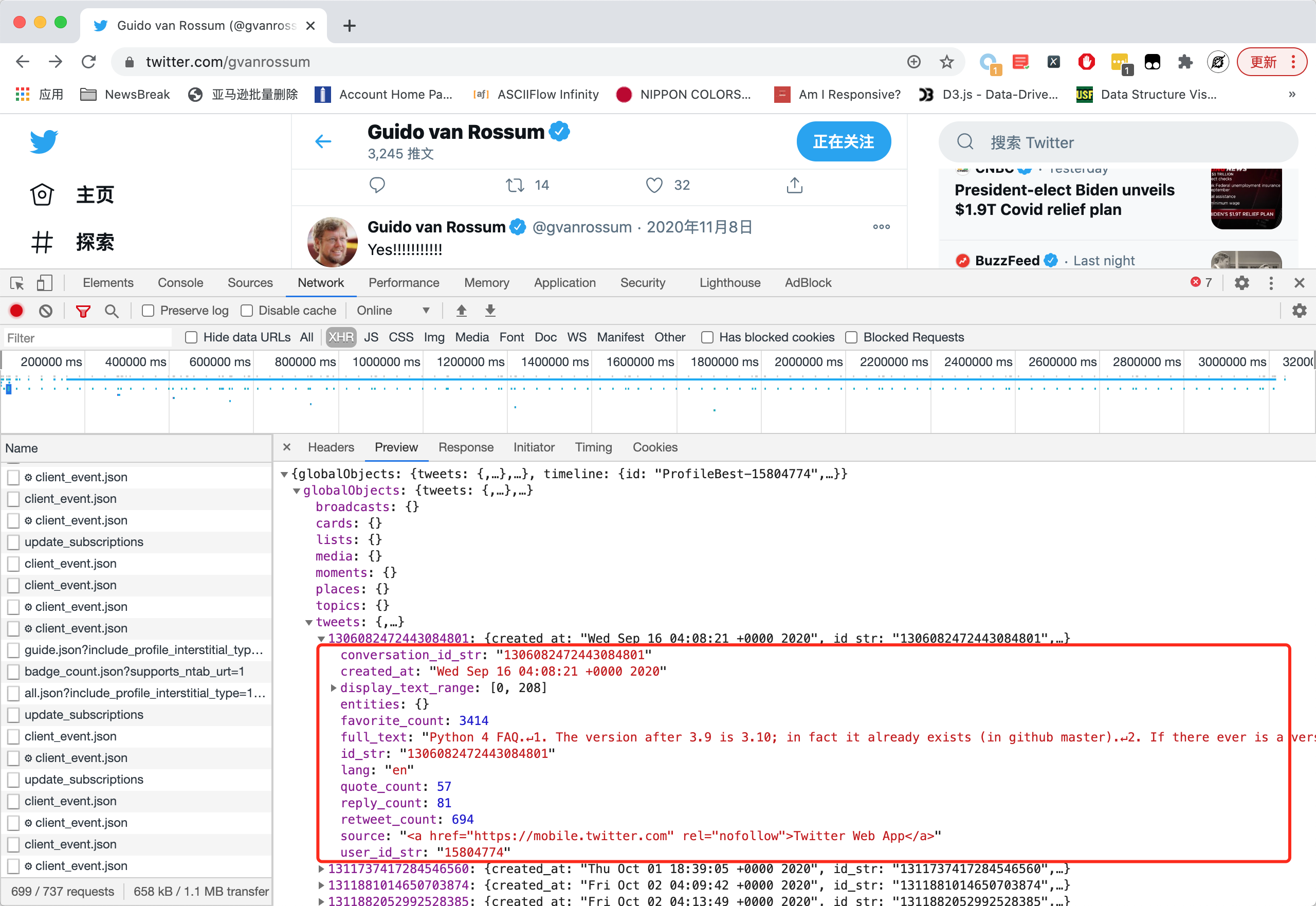
在爬虫开发的过程中,我们经常遇到一些 Ajax 加载的接口会返回 JSON 数据。如下图所示,是 Twitter 的用户时间线接口,返回了一段3000多行的深层嵌套 JSON:

其中的cursor这个字段,是请求下一页的必要字段,我必须把它的 value 值读取出来,拼接到请求 URL 中,才能请求下一页的内容。
现在问题来了,cursor字段在这个 JSON 里面的哪个位置?从最外层开始,我应该怎么样才能读取到最里面的这个cursor中的value字段的值?
我知道已经有一些第三方库可以直接根据字段名读取 JSON 内部任意深度的值,不过用别人的东西总没有自己写一个轮子来得过瘾。所以今天我们自己来手写一个模块,我把他叫做JsonPathFinder,传入一个 JSON 字符串和需要读取的字段名,返回从最外层开始直到这个字段的路径。
效果演示
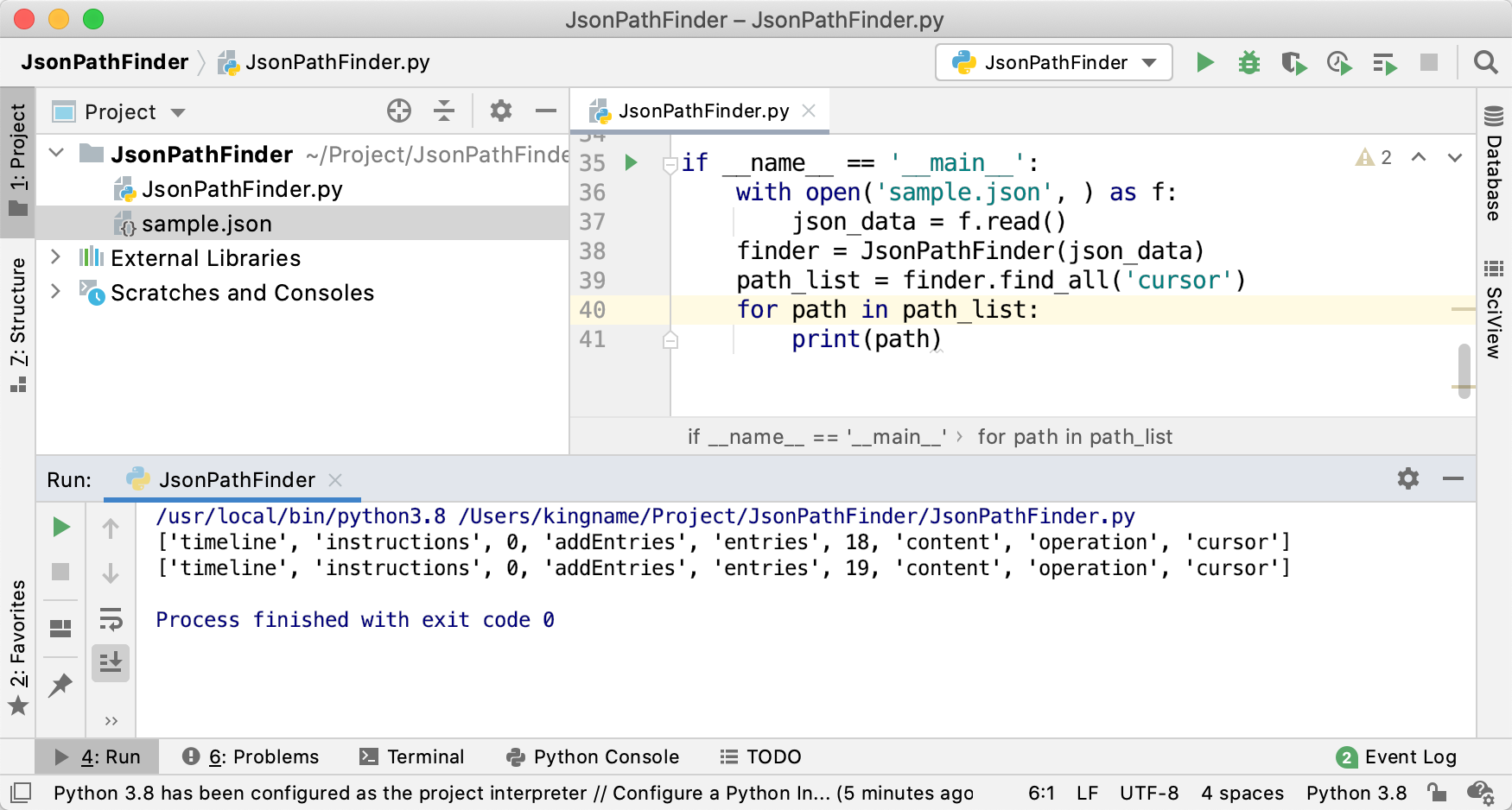
我们用 Python 之父龟叔的 Twitter 时间线来作为演示,运行以后,效果如下图所示:

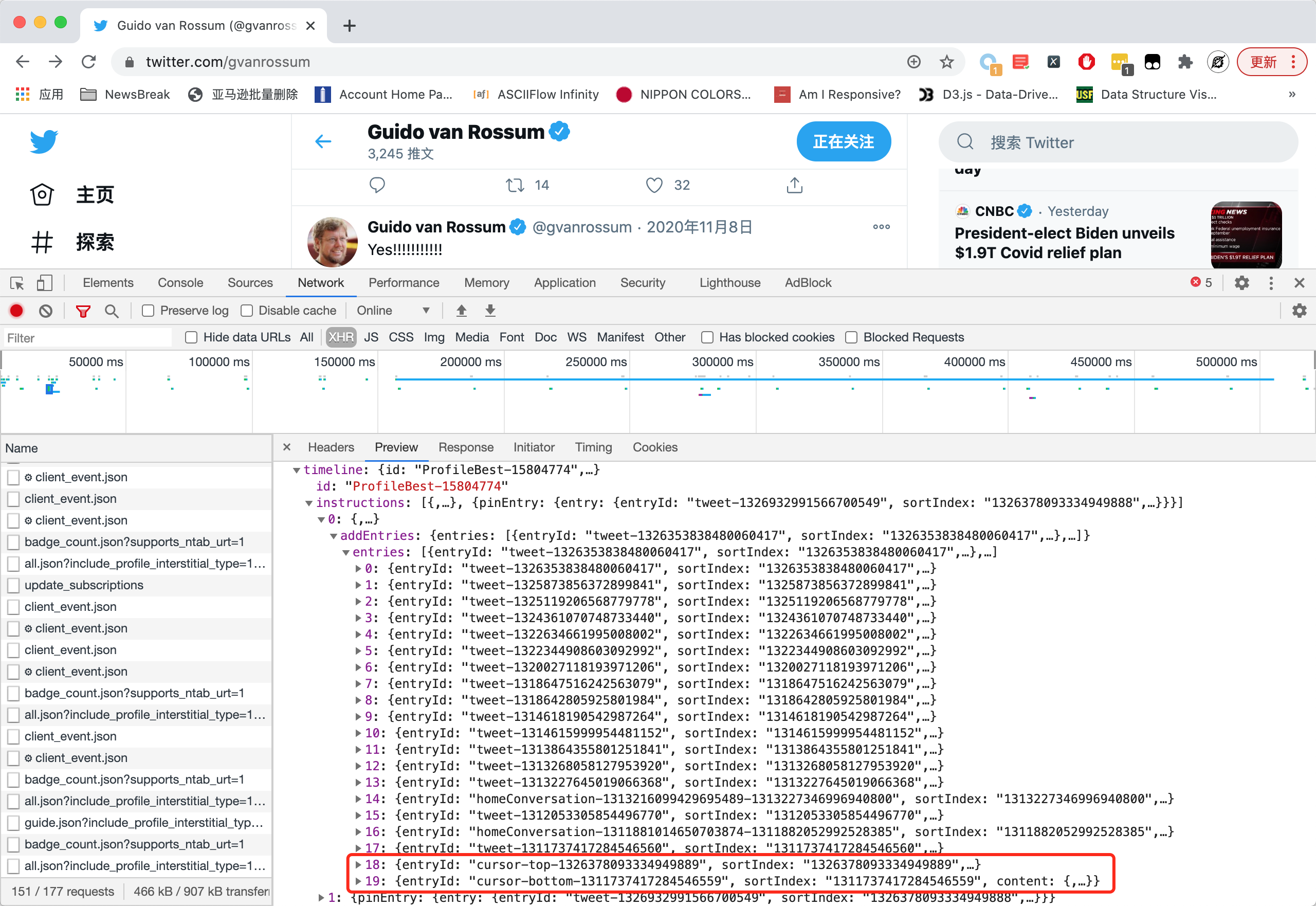
可以看到,从最外层开始一路读到cursor字段,需要经过非常多的字段名,对应到 JSON 中,如下图所示:

由于entries 字段列表中一共有20个元素,所以这里的18、19实际上对应了倒数第二条和倒数第一条数据。其中,倒数第二条的 cursor 对应的是本页第一条推文,而倒数第一条对应的是本页最后一条推文。所以当我们要往后翻页的时候,应该用的是倒数第一条的 cursor。
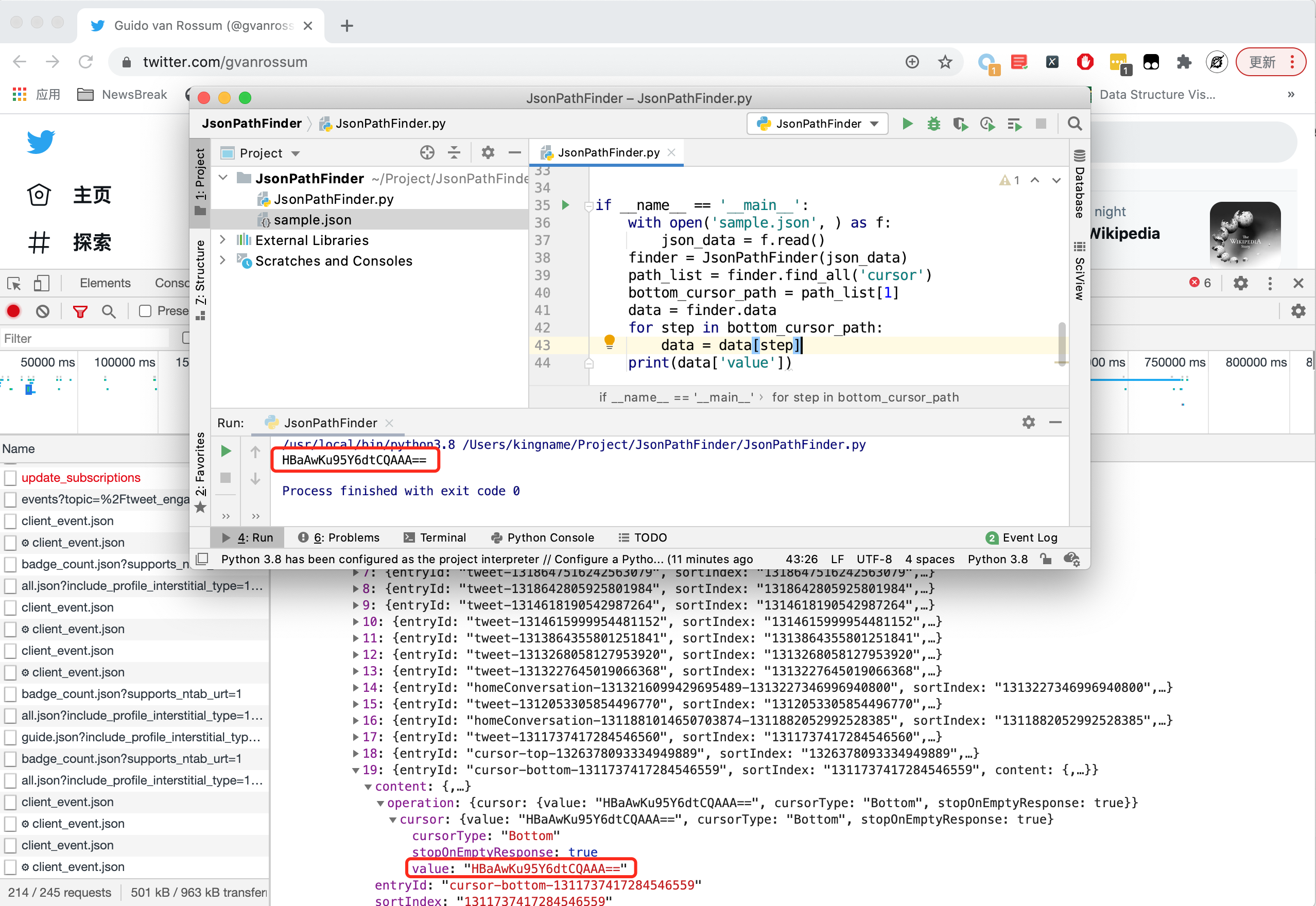
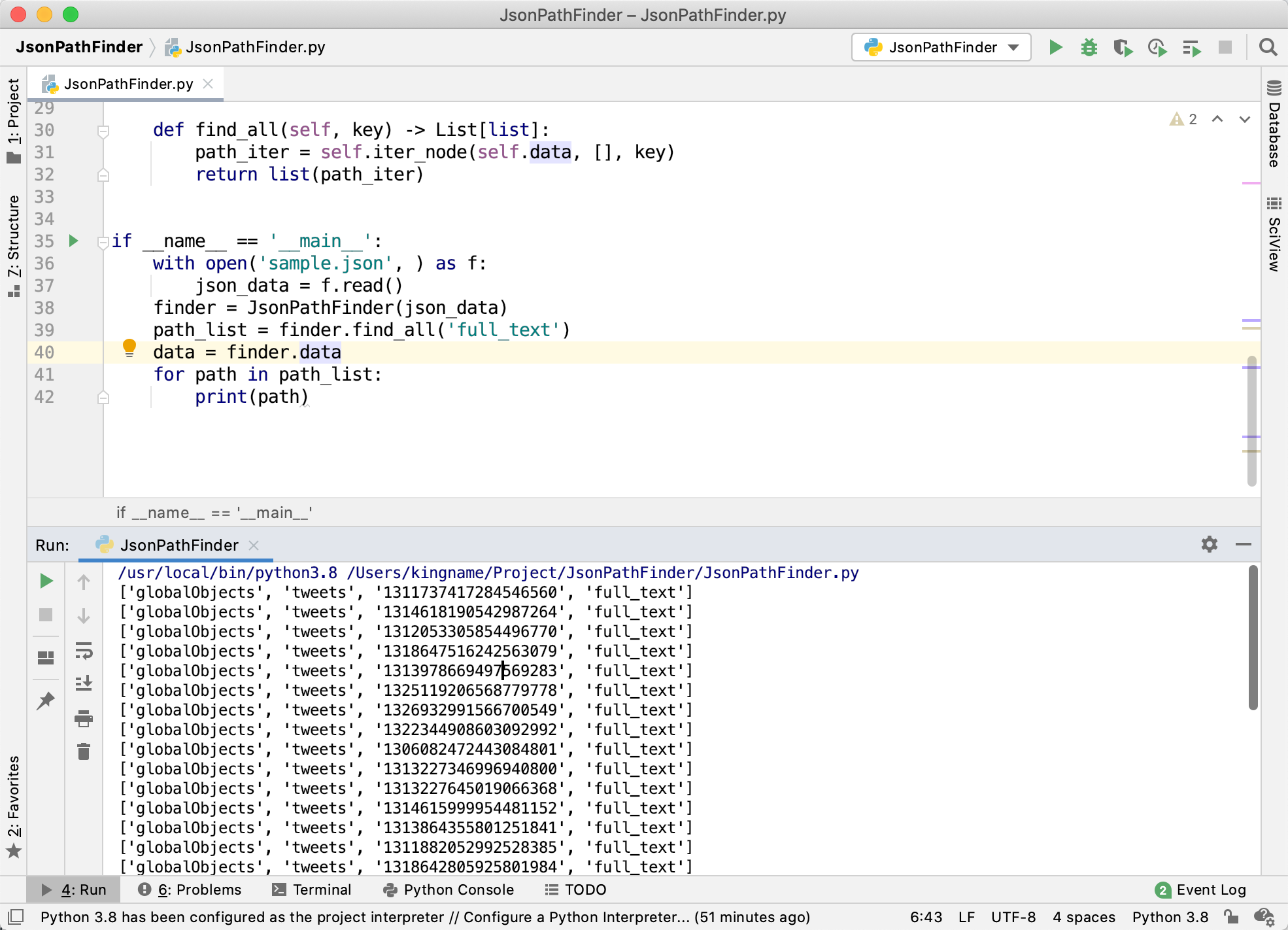
我们试着来读取一下结果:

非常轻松地获取到了数据。不需要再肉眼在 JSON 中寻找字段了。
原理分析
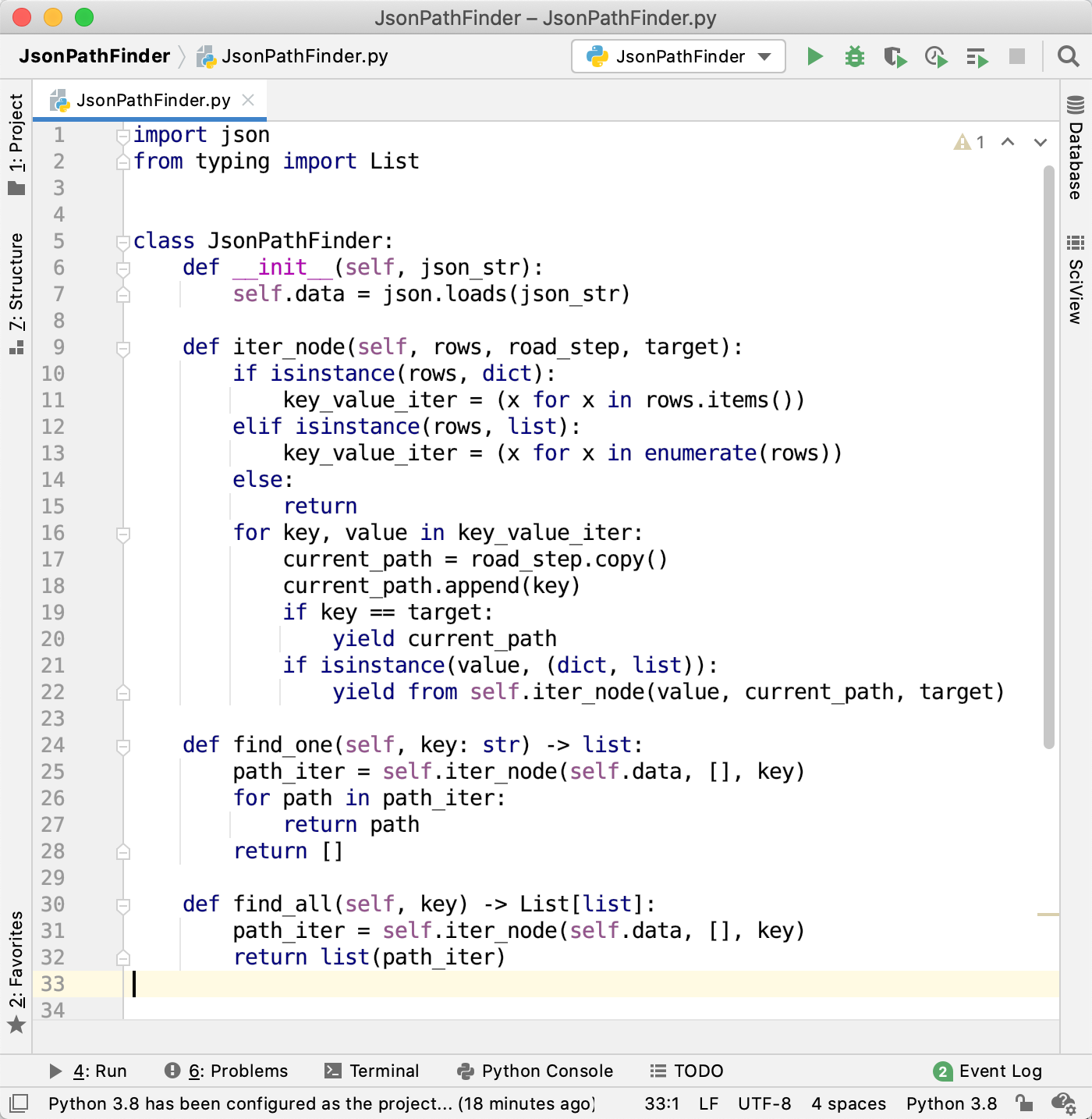
JsonPathFinder 的原理并不复杂,全部代码加上空行,一共只有32行,如下图所示:

因为一个字段在 JSON 中可能出现很多次,所以find_one方法返回从外层到目标字段的第一条路径。而find_all方法返回从外层到目标字段的所有路径。
而核心算法,就是iter_node方法。在把 JSON 字符串转成 Python 的字典或者列表以后,这个方法使用深度优先遍历整个数据,记录它走过的每一个字段,如果遇到列表就把列表的索引作为 Key。直到遍历到目标字段,或者某个字段的值不是列表也不是字典时结束本条路径,继续遍历下个节点。
代码第10-15行,分别对列表和字典进行处理。对于字典来说,我们分离 key 和 value,写作:
for key, value in xxx.items():
... 对于列表,我们分离索引和元素,写作:
for index, element in enumerate(xxx):
... 所以如在第11和第13行,使用生成器推导式分别处理字典和列表,这样得到的key_value_iter生成器对象,就可以在第16行被相同的 for 循环迭代。
我们知道,在 Python 里面可以迭代的对象除了字典和列表以外,还有很多其他的对象,不过我这里只处理了字典和列表。大家也可以试一试修改10-15行的条件判断,增加对其他可迭代对象的处理逻辑。
代码第16-22行,对处理以后的 key-value 进行迭代。首先记录到当前字段为止的迭代路径到current_path列表中。然后判断当前字段是不是目标字段。如果是,那么把当前的路径通过 yield 抛出来。如果当前路径的值是列表或者字典,那么把这个值递归传入 iter_node 方法,进一步检查内部还有没有目标字段。需要注意的是,无论当前字段是不是目标字段,只要它的值是列表或者字典,都需要继续迭代。因为即使当前字段的名字是目标字段,但也许它内部还有某个子孙字段的字段名也是目标字段名。
对于普通函数来说,要递归调用,直接return 当前函数(参数)就可以了。但是对于生成器来说,要递归调用,就需要使用yield from 当前函数名(参数)。
由于iter_node方法返回的是一个生成器对象,在 find_one和find_all方法中,for 循环每一次迭代,都能拿到一条从20行抛出来的到目标字段的路径。而在find_one方法中,当我们拿到第一条路径时,不再继续迭代,那么就可以节省大量的时间,减少迭代次数。
正确使用
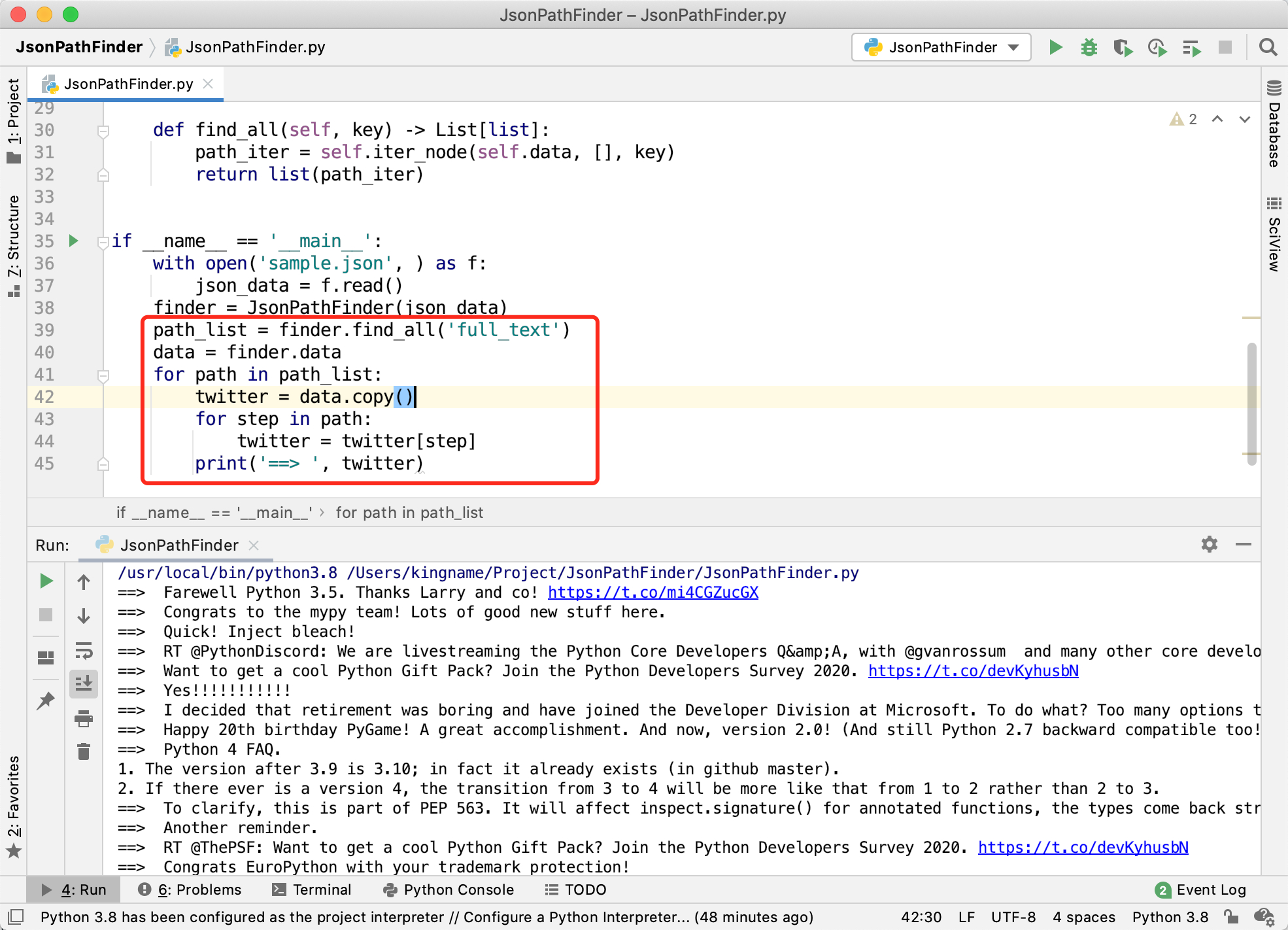
有了这个工具以后,我们可以直接用它来解析数据,也可以用来辅助分析数据。例如,Twitter 时间线的正文是在full_text中,我可以直接用 JsonPathFinder 获取所有的正文:

但有时候,我们除了获取正文外,还需要每一条推文的其他信息,如下图所示:

可以看到, 这种情况下,我们可以先获取从外层到full_text的路径列表,然后再人工对列表进行一些加工,辅助开发:

从打印出来的路径列表里面可以看到,我们只需要获取globalObjects->tweets就可以了。它的值是20个字典,每个字典的 Key 是推文的 ID,Value 是推文的详情。这个时候,我们再人工去修改一下代码,也能方便地提取一条推文的全部字段。
致谢
感谢 @antx-code 同学的建议,Add find mode,增加按 Value 搜索的功能。

|

 客服电话
客服电话
 APP下载
APP下载

 官方微信
官方微信















请发表评论