This project was open-sourced by Kapost, a content operations and marketing platform developed in beautiful Boulder, CO. We're hiring—join our team!
GraphQL API Gateway
This project is an example API Gateway over GraphQL, implemented with Apollo Server 2. The API Gateway here is a service that proxies and resolves requests to join data from different services. In this example, we join data over REST-like JSON APIs from two different example back-end services—service1 and service2. In this example, we show some performance and safety mechanisms used to provide data in a consistent shape under a strongly-typed GraphQL schema ready for clients to use. See the service1 and service2 READMEs to see what the mock API endpoints look like.
This API Gateway implementation shows examples of HTTP caching, error formatting, model organization, defending against bad data, mocking data, and tracking over statsd. It also includes tools for easily mocking portions of queries with different sets of mock data. This allows front-end developers to independently build features while other service APIs are still being developed; and can serve as a predictable, non-changing data set for apps when integration testing. We hope this code can serve as a reference to you to implement some of these features as you become familiar with Apollo Server.
This code is provided as-is without some things to be production ready. We note that this example does not include things like query scoring or rate limiting, and assumes being behind a proxy in production as it does not protect against malicious headers or attempt to rate limit. The routing is also hardcoded and would need to be adjusted for real deployment. It does not have an implementation for connections or schema stitching, but these features shouldn't be too difficult to add with the Apollo Server docs.
You should have node@>=8.11 and redis installed. Ensure you do not use older versions of node with (you can manage node versions across projects with asdf, nodenv, nvm or n). If you have installed redis through homebrew or other package managers, it should just work while running on the default ports with no additional configuration. You should set the REDIS_URL variable (with username, ports, passwords, etc) in your .env.local if you need any different config.
Once installed, running the app is as simple as:
yarn install
yarn start
This will serve the /graphql endpoint. You can also go to the GraphQL Playground (if NODE_ENV !== production) at localhost:3080.
ENV flags for development
We provide a few flags for testing and debugging various aspects of the server.
DEBUG_REQUESTS=1
Logs out requests by each async time step
DEBUG_EXTENSIONS=1
Adds all extensions to output, including tracing information. Turn this on to see performance timing for resolvers.
MOCK_SERVER=1
Turns on mocks for the entire schema (no resolvers will run)
MOCK_MISSING_RESOLVERS=1
Mocks out data from any resolvers that are not present (useful for new development)
DISABLE_HTTP_CACHE=1
Prevent caching any cacheable HTTP requests.
You can run these by setting the env flag before yarn start, i.e.
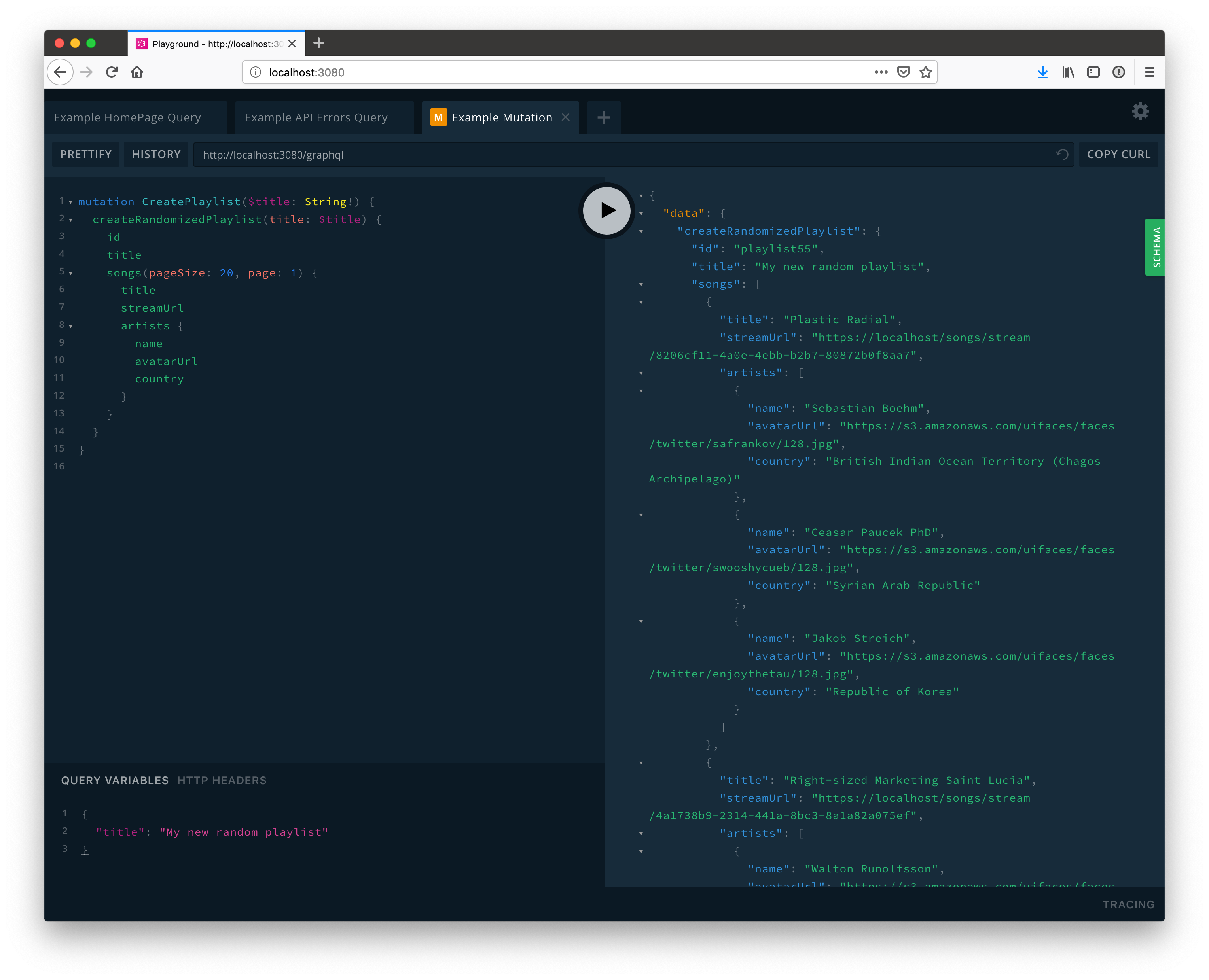
All GraphQL queries and mutations start from special types called query and mutation. You can start by querying any field on one of these types and continuing down until you have selected "terminal", scalar fields. For example, we may query the field currentUser with a query like the following.
In general, prefer always including both the keyword and name, since we can use the given name to monitor query performance and counts.
For most client queries, you will need to query with run-time variables rather than hardcoding values in the query. You can do this by adding typed arguments to the root query and using them within. Ensure you match the type signatures of the query arguments to the field arguments.
The GraphQL Playground has an area for adding query variables as JSON. For an more in-depth guide
on writing queries (including other query features), please review the official query GraphQL tutorial.
Fetching from clients
This GraphQL service is served over HTTP, which means there is no requirement to use anything other than HTTP calls. We can ask for GraphQL data simply by using libraries such as axios or fetch. There are several popular GraphQL client libraries that have sophisticated features such as client-side caching and GraphQL query batching. These libraries or similar ideas may be used if they fit into an existing react/redux stack, but existing HTTP fetching abstractions will work as well.
Browser / NodeJS
The GraphQL endpoint is served as a POST endpoint on /graphql. You need to provide the following post data:
query — the text of the GraphQL query
variables — (optional) a JSON object of query variables provided
Additionally, you will need to provide authorization in the form of a browser cookie, JWT (Authorization header), or basic auth API tokens (also the Authorization header).
If configured in webpack or other bundlers, you could also import .graphql files in our front-end apps to avoid defining large queries in JavaScript strings.
Just like JavaScript, you can fire a HTTP POST request with whatever networking solutions you have in your app already. There are also some GraphQL clients that can fire requests with nicer features such as the graphql-client gem. If you are looking for other options, remember you are looking for a GraphQL client library and not building another GraphQL server.
Error handling
Type of errors
Network errors (? status code)
Server errors 500 (entire query missing)
Resolver errors (per-field errors)
HTTP errors (401, 403, 404)
API Gateway proxy errors (400)
Unexpected errors
Since the GraphQL response undertakes many sub-requests, it can often be more work to parse apart all the various possible error states. Thankfully, a fairly naive approach to all of these errors is usually good enough. From a client's perspective, it often makes sense to bucket these errors into the following categories:
Lost network connection
Failed (with or without retry)
Missing data (may or may not be ok depending on path)
Naively, we can usually escalate missing data to failed. Since GraphQL is strongly typed, this means we will have an errors object.
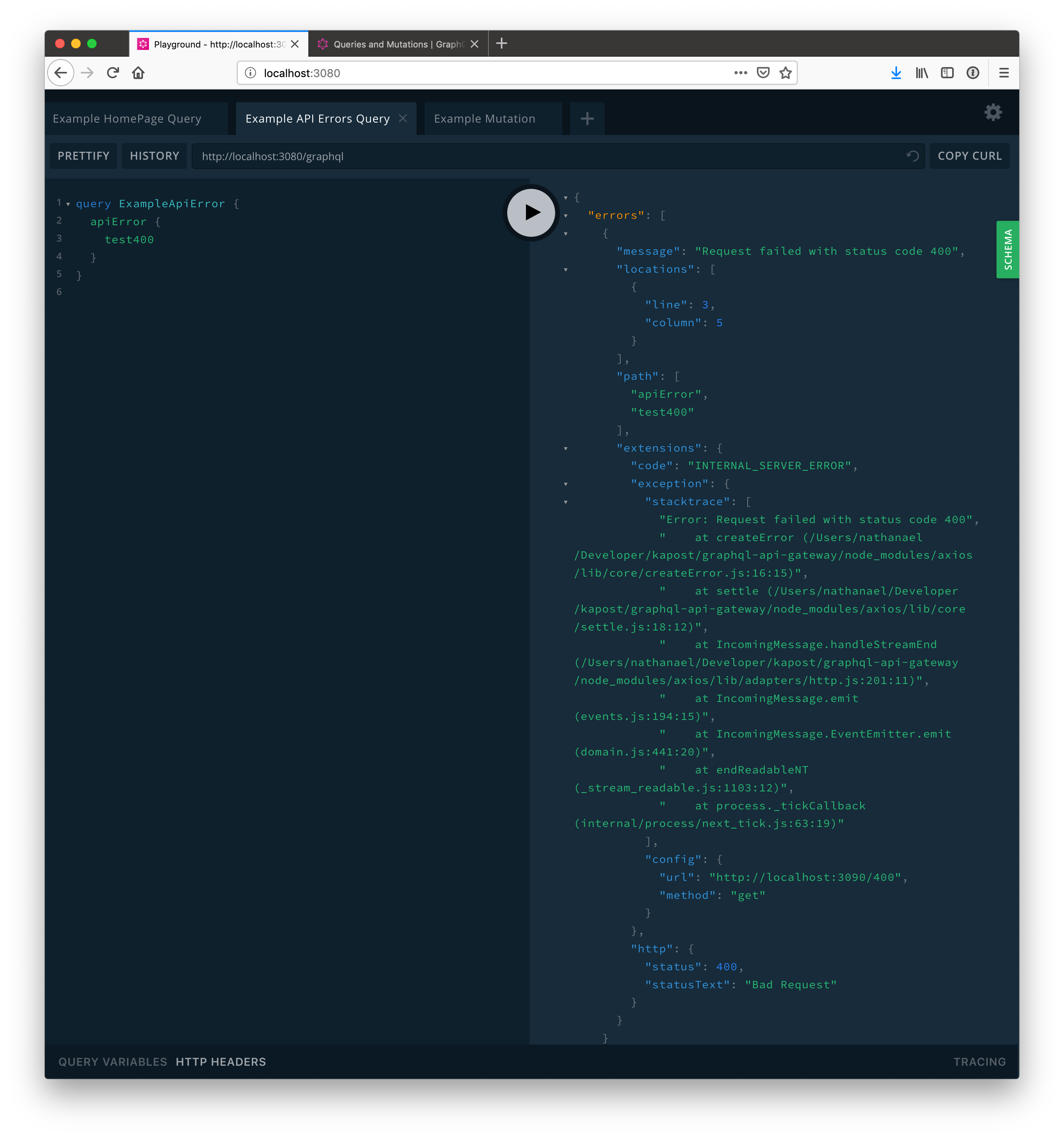
When there are errors, a GraphQL response may look like this. The stacktrace and message will be omitted in production to avoid leaking information to consumers.
GraphQL is strict and will cut off data when there are errors in type matching. If there are multiple error objects, you may be able to use a partial response depending on your use case. Remember that a 200 status code for a GraphQL request may still mean there were proxy HTTP errors! Always check for a errors key in response.
For most use cases, the following pseudocode is appropriate for bucketing errors in clients for user action:
If the axios request does not have data / status
Network error (please try again, internet down) or retry
400/500 status from /graphql request
Service error
Any errors object?
Any HTTP 401 error
Unauthenticated Error
Any HTTP 403 error
Unauthorized Error
Any HTTP 404 error
NotFound Error
Other
Service error
We recommend extracting this error handing logic into a shared function / package to avoid repeating this same error handling in your clients.
Mocking data for development
As mentioned above, you can mock out data with the MOCK_SERVER=1 or MOCK_MISSING_RESOLVERS=1 env variables. When present, the graphql-tools library will simulate building types. All types can be emulated automatically. Custom scalars will need to be defined under the mocks folder.
Note that you can also build a "temporary" resolver for new work that simply returns a fixture or some generated object while working on new development.
For more info on how mocking works in graphql-tools, please review their documentation.
Exporting entire schema
If you have a use for the full GraphQL schema, you can export statically with yarn run export:schema. The outputted file will be available as schema.graphql at the root. This may be useful in future for tooling, type checking in editors, or schema stitching.
Development
Before developing, we recommend going through the GraphQL Tutorials on their official site.
Key concepts and definitions
Query (uppercase)
The special root type in GraphQL schema which is the start of all GraphQL fetches. This is what you write to define what data types are available.
query (lowercase)
A client side query (with optional variables) that is sent and resolved to return data. This is what you write to get data for clients.
Mutation — depending on context can mean either:
The special root type in GraphQL schema which is the start of all GraphQL fetches
mutation (lowercase)
A client side mutation (with optional variables) that is sent and resolved to return data. This is what you write to mutate and then return data from clients.
Subscription
A special root type that represents a query that continually streams back to the client over a protocol such as websockets.
Resolver
A function that returns the proper data for a given ParentType -> field relationships. This function has a constant signature of (obj, args, context, info).
Obj
First argument to resolvers which is the parent object (if given)
Args
Second argument to resolvers which includes all field arguments given (matching the types from the schema).
Context
Third argument including any data / models / etc that is instantiated per request.
Context Args
Rarely, you need to pass down arguments or config down to a future resolver. To do this, we include a special object under context.args for this purpose.
Info
Fourth argument for advanced usage. Includes the query AST which can be used for schema introspection.
Model
An abstraction that represents a way to fetch data in a performant way. Methods are defined to fire requests, batch them via dataloader, and are memoized when possible.
Mock
An "alternate" resolver that can return mock data. Currently, the entire server can be automatically mocked or just missing resolvers.
Mapper
A utility file of common translations for resolvers. Intended to be used with lodash/fp's flow.
Defense
A pattern for removing inconsistent data (bad referential integrity) with Datadog monitoring. Typically used in response or Model objects
Optional
A wrapper for responses that may not return. Models should return data wrapped in optionals to ensure that calling resolvers must unwrap it with must, maybe, or match.
Connector
An abstraction over different data access mechanisms. We currently have just one for HTTP, but could in future have other connectors for a database, memory cache, websocket, etc.
Memoization
A way of improving performance by only calling a method once and storing the result if called again. This service heavily uses this pattern through memoizationByArgs, which does an efficient deepEquals on all arguments to cache calls during a request.
Tracing
Data that is provided through the apollo-server package. It automatically times each resolver and returns timing data to help identify slow areas.
Adding and extending schema
Again, we recommend going through the official schema guide to understand the major language syntax and keywords.
At it's core, GraphQL schema is simply a collection of type definitions. There are core, basic types called scalars. Examples of built-in scalars include ID, Boolean, Int, and String. Developers can build up a rich set of types by composing these scalars into grouped object types with the type keyword. In addition to types, other definitions can be made including:
scalar — A keyword to define make additional scalars. Custom scalars must include a JS definition for parsing and serializing.
enum — A set of named, constant options. Should always be in UPPER_CASE.
union — A way of combining types into a set of possible types for polymorphic types and lists of different types
interface — Another way of combining types, where a base type is defined and can be extended via implements
GraphQL schemas also require separate type definitions around any input types that are used for field arguments. These are defined with the input keyword. Currently (in GraphQL 0.13), the input type is considerably more limited in definition and can only include scalars, other input types, and enums. This will likely be extended in an upcoming spec update.
GraphQL also includes a specification for directives, which are attributes you can attach to type field. Most common is the @deprecated directive, which signals that the field is a candidate for removal and should be not be used going forward.
Custom scalars
Scalars are good for representing "terminal" data in custom shapes—usually we don't want to make objects scalars. For example, we add the URL, Date, and DateTime scalars to represent strings with special, specifically-defined shapes.
Designing Input Schema
GraphQL requires separate Input types for any objects that are passed into field arguments. These types are defined with the input keyword and can be composed like other types.
In general, try to keep the inputs and outputs as close together as possible but omit denormalized data in the input version.
Resolving data
Resolvers represent how to get data on schema fields, or the edges of the graph. We define ParentType -> field relationships which define how to get data for each field requested. These are functions of the following shape:
functionresolver(obj,args,context,info){// return field data in shape of schema}
where
obj is the parent object, if available
args is an object of field arguments, if any
context is an request-wide object that can contain anything (model instances, loggers)
info is an advanced object that contains the full query AST for advanced use
Resolvers can be async to fetch data from external locations (via models) and generally following a pattern similar to the below.
Apollo-server (the package running the resolution program) will properly halt with async resolvers. You do not need to worry about HTTP errors as they will automatically propagate up to the request runner and are formatted via formatError. All resolvers will be called, so you can debounce requests with a tool like dataloader in the model (see Models).
In a lot of cases, it's good to have resolvers return results in a one-to-one shape with the GraphQL schema. This allows you to use implicit resolver that is provided when no resolver for the ParentType -> field pair is given. This default is essentially an identity function where it tries to access the field name on the parent object.
By example
For example, if you had schema like the following:
and then remove the UserProfile.avatarURL resolver. Remember that resolvers should be consistent in their parent object down different fetch paths so you should think through the intermediate resolver return shapes.
Resolving Enums
When resolving an enum, ensure that the string you return from JavaScript matches the enum exactly (capitalized).
When you have a polymorphic type like a union or interface, you must define a special resolver on the type to resolve the actual type. For example, if we had a union like the following:
The return value must be the type name (properly capitalized). To add to the set of resolvers, you must put this under a Type.__resolveType relationship.
To access data from APIs, we use an abstraction called a Model to represent a resource to fetch from another service. Models encapsulate different API calls and are a place to memoize, batch together requests, and return API results in a nice Response object for consistent access.
Response objects
Different services (and even the same service) end up returning responses in inconsistent shapes. For example, paginated service1 responses are in the following shape:
where service2 has a different shape. Rather than return raw objects, we use a Response base class that defines some core methods to get the data block and pagination block. It defaults to camelCasing your response and has different ways of access the data within.
Methods on Response instances:
data()
Returns the camelCased "actual data" from the response
headers()
Returns the camelCased headers from the response
pagination()
If available on the Response subclass, will return the camelCased pagination data (transformed into GraphQL shapes for convenience)
keyBy(key, path?)
returns the object keyed by a properly like lodash. If a path is given it will key by an object within.
find(key, value, path?)
Similar to keyBy, it does an efficient lookup under some key, matching by value. If a path is given the search will be under that path.
Properties on Response instances:
raw
If necessary, this is the raw, un-camelized response. You generally shouldn't need this.
All the response methods are memoized by arguments (meaning the result is stored for any arguments that are deep equals). This means we can keyBy with ease without worrying about calling repetitively over many resolvers.
When interacting with new services, you should add a subclass if necessary to encapsulate the response. Additionally, for some responses that return arrays via batches, models can map responses for each individual result that still has the pageInfo and headers for consistent access.
Batching
There are frequently cases where resolvers in a list need to fetch from the API but it would be prohibitively expensive to fire an individual request within sub-query resolver. To keep resolvers simple and one-to-one, we use a tool called DataLoader in models to essentially debounce and combine requests into one batch. This is a JS library from Facebook, but please use the helper in utility/createDataLoader to ensure that we batch by deep equals for arguments.
Typically, you would use data loader instance within a class to batch together get and getMany methods like the following. Additionally, DataLoader will cache any fetched items so you will be able to immediately get back an item that has been fetched during the request already.
In some models, it may not make sense to use data loader but you may still want to memoize. This helper ensures that for any set of arguments that deep equal, a previous result will be returned if computed already.

 客服电话
客服电话
 APP下载
APP下载

 官方微信
官方微信

















请发表评论