开源软件名称:BusinessMQ
开源软件地址:https://gitee.com/chejiangyi/Dyd.BusinessMQ
开源软件介绍:
##分支说明## 该分支是基于BSF的基础上开发的分支。
修改内容
1)sdk以插件的形式扩展自BSF。
2)项目命名空间从Dyd.BaseService.BusinessMQ修改为BusinessMQ
3) 打包安装包,可以直接被第三方安装使用。
4)若使用旧版本XXF.dll,请则使用master分支
直接使用**“安装包”**下的安装包直接安装试用。
业务消息队列业务消息队列是应用于业务的解耦和分离,应具备分布式,高可靠性,高性能,高实时性,高稳定性,高扩展性等特性。 开源QQ群: .net 开源基础服务 238543768 优点:- 大量的业务消息堆积能力
- 无单点故障及故障监控,异常提醒
- 生产者端负载均衡,故障转移,故障自动恢复,并行消息插入。
- 消费者端负载均衡,故障保持,故障自动恢复,并行消息消费。
- 消息高可靠性持久化,较高性能,较高实时性,高稳定性,高扩展性。
- 支持99*99个消息分区,单个消息分区单天支持近1亿的消息存储。
- 消费者拉方式获取消息,在高并发,大量消息涌入的情况下,只要消费能力足够,不会有消息延迟,消息越多性能越好。
缺点:- 能保证消息顺序插入,保证相同分区的消息是顺序的(排除网络延迟),但是多个分区之间的可能是乱序的。
- 消息并行消费或者多个分区并行消费或者负载均衡情况下的,消息消费顺序是乱序。
缺点原因:- 消息的负载均衡是基于消息的分区存储,故多个分区之间的消息是乱序的,但是相同分区的消息是顺序的。
- 消息的消费者负载均衡也是基于消息的分区进行均衡的,同时单个消费者订阅多个分区的情况下,也可并行进行消费。意味着不同分区的消息的消费是乱序的,但是相同分区的消息消费是顺序的。
缺点解决方案:- 生产者自定义负载均衡算法,按照业务维度(用户,商户)等进行分区(多个用户之间可以消息乱序,单个用户的消息必须是顺序的),不同维度可以指向不同的分区,但是单个维度的消息是可以保证顺序的。
- 本解决方案在故障的情况下,故障会移除某些故障节点,意味着故障节点会立即报错(当然也可自己指定故障节点进行转移,但是转移的节点消息会被提前消费,故障的消息会在恢复故障后重新消费,这样也会出现故障程度上的消息乱序消费)。
- 本解决方案在线上无缝扩容和扩展性能方面也会有限制,看要具体的负载均衡算法,但是一般情况下,如果要扩容还是会进行部分消息迁移的情况。
问答:1.大量的业务消息堆积能力,如何实现?每个分区表支持约1亿的消息存储,可以通过增加分区表进行扩容。消费者进行消息消费,内部仅保留某个分区上一次消费的指针,所以不会影响消费者。消息持久化到磁盘,不会在内存驻留,理论上不影响内存。 2.无单点故障及故障监控,异常提醒?故障一般会发生在redis,数据节点,管理中心,日志中心。redis节点故障会影响消费者的消息消费响应及时度,一般延迟5s以内。不会影响消息消费速度和消息消费QPS数据节点故障会影响生产者和消费者的消息,并造成消息暂时丢失(但是都是可恢复的,具体的看数据库的高可用做到什么程度)。生产者端会无缝的进行节点移除,但是会默认1分钟重新尝试重连。消费者会持续报错至日志中,但是不会影响其他分区消费。管理中心故障会影响生产者和消费者的心跳检测和新注册的生产者,消费者,但不会影响生产者和消费者具体的消息存储和发送接收。日志中心故障不会影响生产者和消费者,但是影响日志的打印,日志中心故障会通知公司内部监控平台。虽然故障不会影响线上已有的消息运行,但是还是会在高并发情况下出现性能问题,和系统稳定性,所以一旦发现要重视和及时处理。 3.生产者端负载均衡,故障转移,故障自动恢复,并行消息插入?默认负载均衡采用多个分区顺序轮询插入,在并发情况下轮询插入是并行插入到不同分区的;某个数据节点出现故障,会移除相关数据节点的所有分区;默认1分钟会重新载入故障分区进行重试。 4.消费者端负载均衡,故障保持,故障自动恢复,并行消息消费。默认消费者端负载均衡是根据消费者订阅的分区进行的(一个消费者可以订阅多个分区,多个相同业务的消费者可以订阅多个不同分区进行负载)。一个消费者订阅多个分区,这个消费者可以开启并行进行多分区消费。并行度=分区数,效果理论上最佳。分区节点出现故障等,单个分区或者数据节点就会暂停消费,并通知日志中心打印错误日志。当故障恢复后,消费继续进行。 5.消息高可靠性持久化,较高性能,较高实时性,高稳定性,高稳定性。消息传递到消息中心后,立即持久化到磁盘,故不会丢失消息。生产者可以采用多个分区进行并行插入,消费者可以采用并行进行消息消费,故理论上性能是可扩展无限量的。消息是通过拉取的方式获取的,发送消息会由redis进行即时通知消费者拉取(即时消息默认会合并在500ms内redis通知消息),一般在20ms内消息会被消费掉。批量拉消息的方式相对push的消息推送方式在高并发和大量消息处理的情况下,消息发送性能应该是更优的。稳定性是基于数据库的稳定性和故障转移层面来确保的,扩展性体现在线上无缝的迁移和扩容。 6.支持9999个消息分区,单个消息分区单天支持近1亿的消息存储。数据节点是0199个,节点里面的表分区是0199个,所以可以支持近1万个分区节点。单表的mqid最大应该是(1亿-1)条,应该满足一般的业务需求,若不能满足,可以通过多个分区的方式扩容。 7.消费者拉方式获取消息,在高并发,大量消息涌入的情况下,只要消费能力足够,不会有消息延迟,消息越多性能越好。push推消息的模式能保证更高的实时性,但是在大量消息的情况下,消息堆积的情况更严重,性能会有所影响。pull拉消息的模式在保证消息实时性方面会略差,但是在大量消息涌入的情况下,批量拉消息效率更加。而且会将消息分发的负载转移到多个消费者端上。 未来改进:- 未来采用leveldb重写存储。
- 剥离broker服务用于支持相对可靠的消息服务。
- 消息完成标记本地缓存/持久化(或者存储redis),每秒提交更新至数据库,消除频繁消费导致的瓶颈。
使用demo示例 /// <summary> /// 发送消息 /// </summary> /// <param name="msg"></param> public void SendMessageDemo(string msg) { //发送字符串示例 var p = ProducterPoolHelper.GetPool(new BusinessMQConfig() { ManageConnectString = "server=192.168.17.201;Initial Catalog=dyd_bs_MQ_manage;User ID=sa;Password=Xx~!@#;" },//管理中心数据库 "dyd.mytest3");//队列路径 .分隔,类似类的namespace,是队列的唯一标识,要提前告知运维在消息中心注册,方可使用。 p.SendMessage(@"1"); //发送对象示例 /* var obj = new message2 { text = "文字", num = 1 }; var p = ProducterPoolHelper.GetPool(new BusinessMQConfig() { ManageConnectString = "server=192.168.17.237;Initial Catalog=dyd_bs_MQ_manage;User ID=sa;Password=Xx~!@#;" },//管理中心数据库 "test.diayadian.obj");//队列路径 .分隔,类似类的namespace,是队列的唯一标识,要提前告知运维在消息中心注册,方可使用。 p.SendMessage<message>(obj); */ } private ConsumerProvider Consumer; /// <summary> /// 接收消息 /// </summary> /// <param name="action"></param> public void ReceiveMessageDemo(Action<string> action) { if (Consumer == null) { Consumer = new ConsumerProvider(); Consumer.Client = "dyd.mytest3.customer1";//clientid,接收消息的(消费者)唯一标示,一旦注册以后,不能更改,业务下线废弃后必须要告知运维,删除消费者注册。 Consumer.ClientName = "客户端名称";//这个相对随意些,主要是用来自己识别的,要简短 Consumer.Config = new BusinessMQConfig() { ManageConnectString = "server=192.168.17.201;Initial Catalog=dyd_bs_MQ_manage;User ID=sa;Password=Xx~!@#;" }; Consumer.MaxReceiveMQThread = 1;//并行处理的线程数,一般为1足够,若消息处理慢,又想并行消费,则考虑 正在使用的分区=并行处理线程数 为并行效率极端最优,但cpu消耗应该不小。 Consumer.MQPath = "dyd.mytest3";//接收的队列要正确 Consumer.PartitionIndexs = new List<int>() { 1, 2, 3,4, 5, 6, 7, 8 };//消费者订阅的分区顺序号,从1开始 Consumer.RegisterReceiveMQListener<string>((r) => { /* * 这些编写业务代码 * 编写的时候要注意考虑,业务处理失败的情况。 * 1.重试失败n次。 * 2.重试还不行,则标记消息已被处理。然后跳过该消息处理,自己另外文档记录这种情况。 * 消息被消费完毕,一定要调用MarkFinished,标记消息被消费完毕。 */ action.Invoke(r.ObjMsg); r.MarkFinished(); }); } } /// <summary> /// 关闭消息订阅连接 /// </summary> public void CloseReceiveMessage() { //注册消费者消息,消费者务必要在程序关闭后关掉(dispose)。否则导致异常终止,要人工等待连接超时后,方可重新注册。 if (Consumer != null) { Consumer.Dispose(); Consumer = null; } }}架构示意图 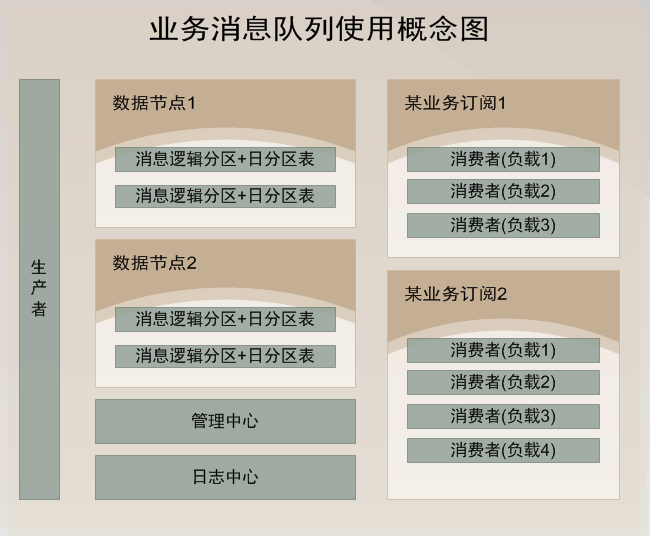  部分界面截图 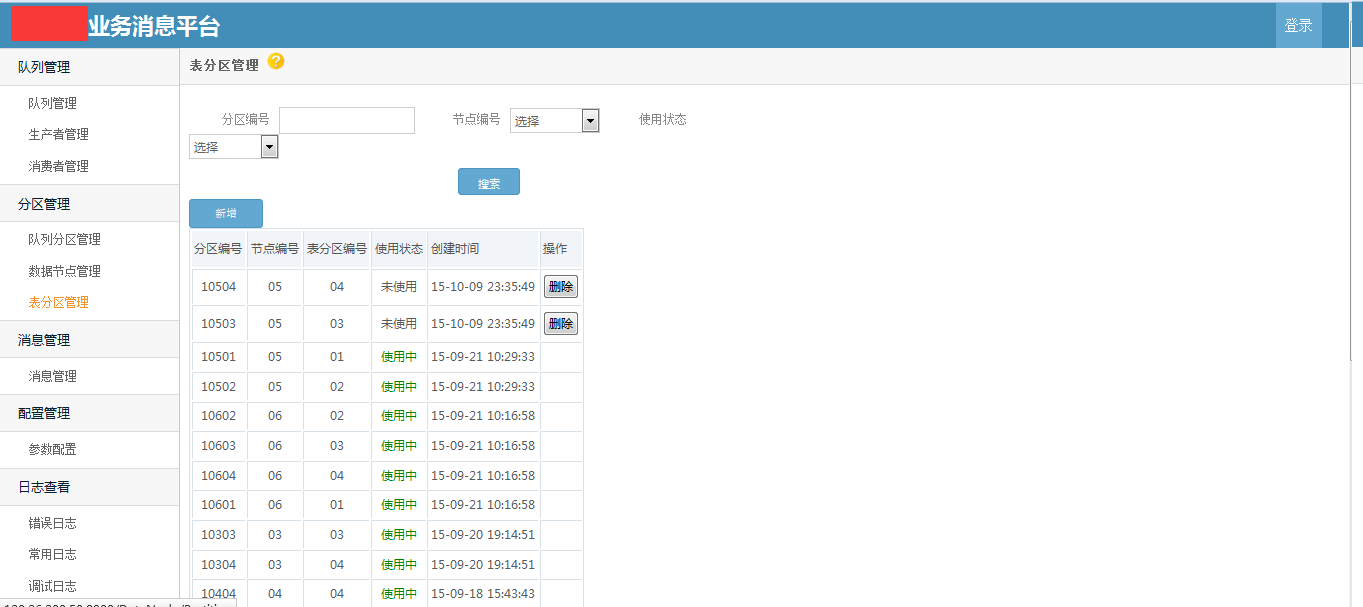 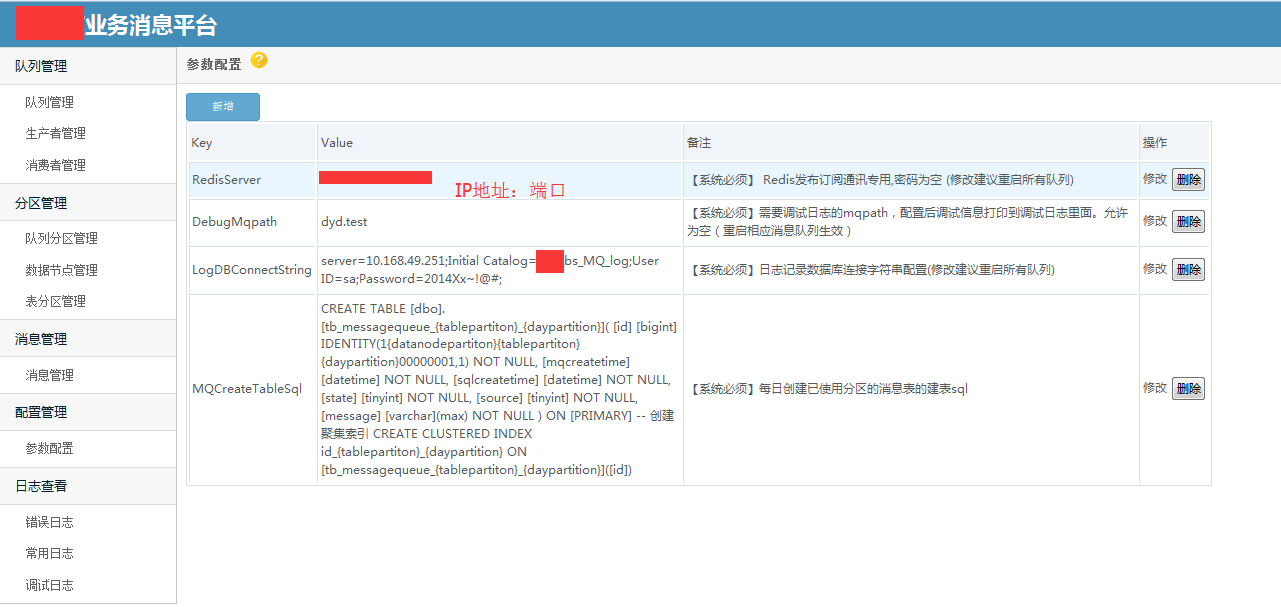 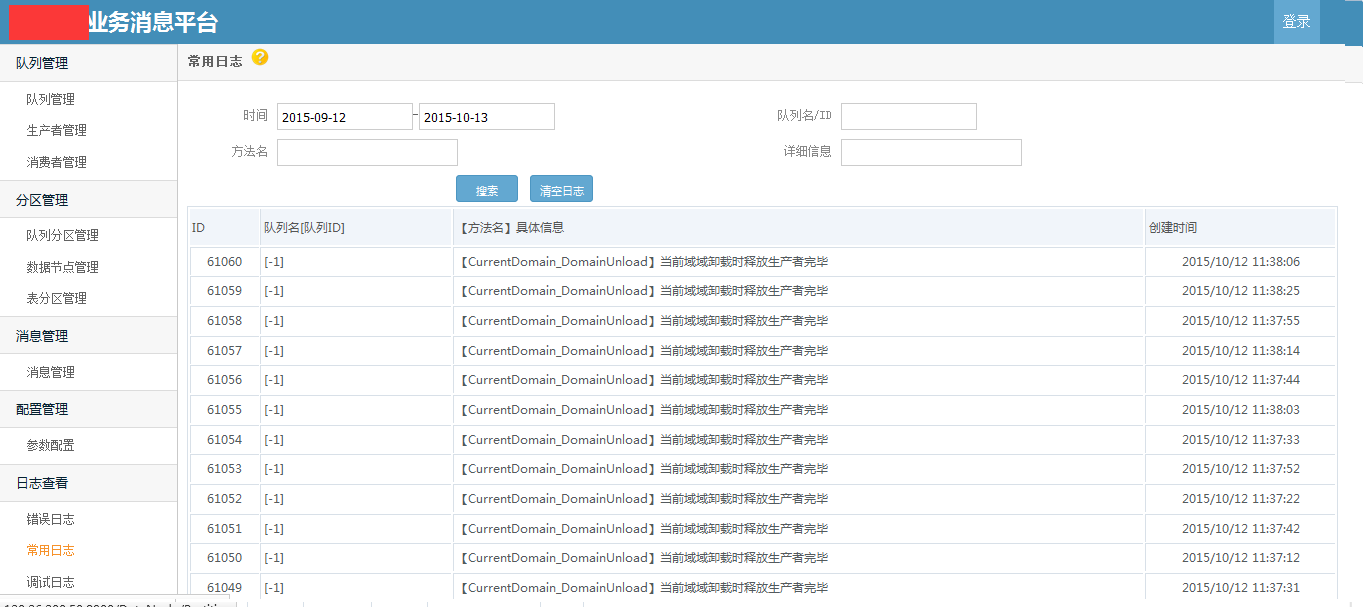 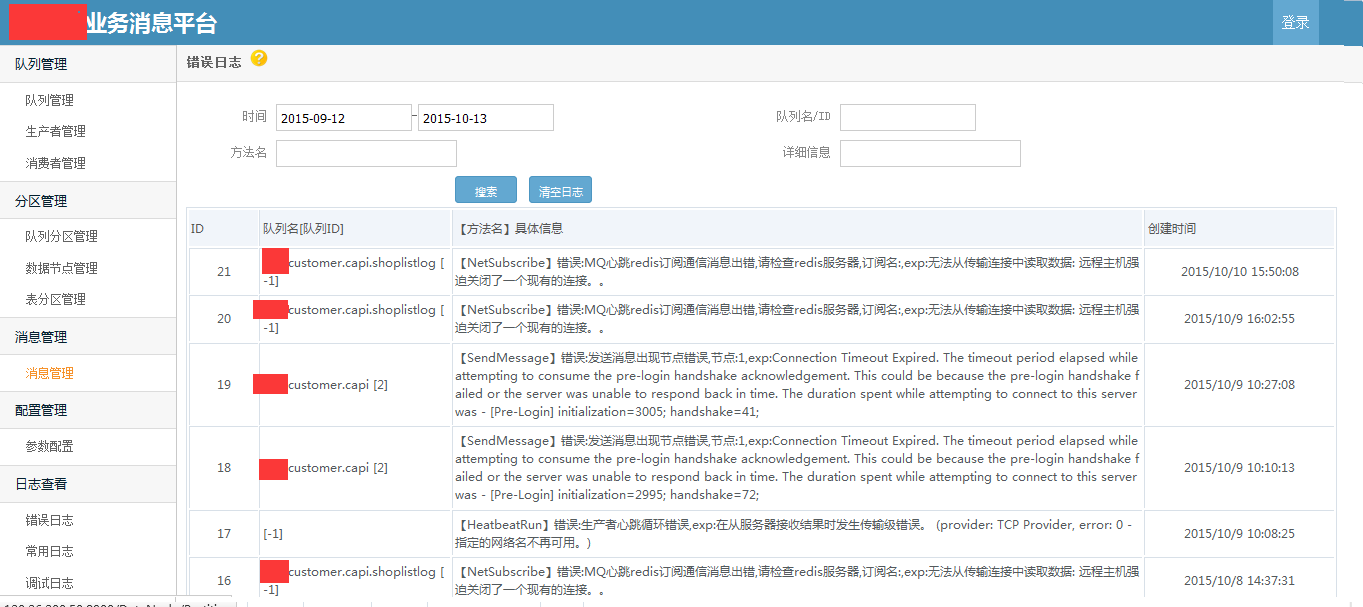 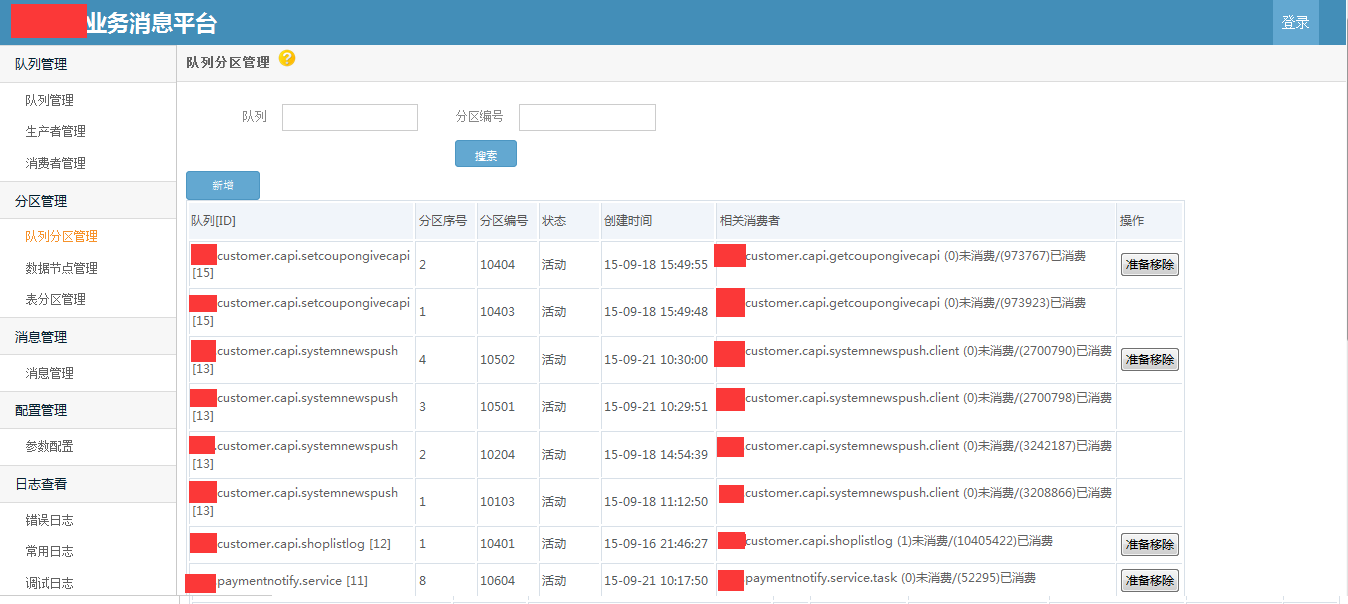 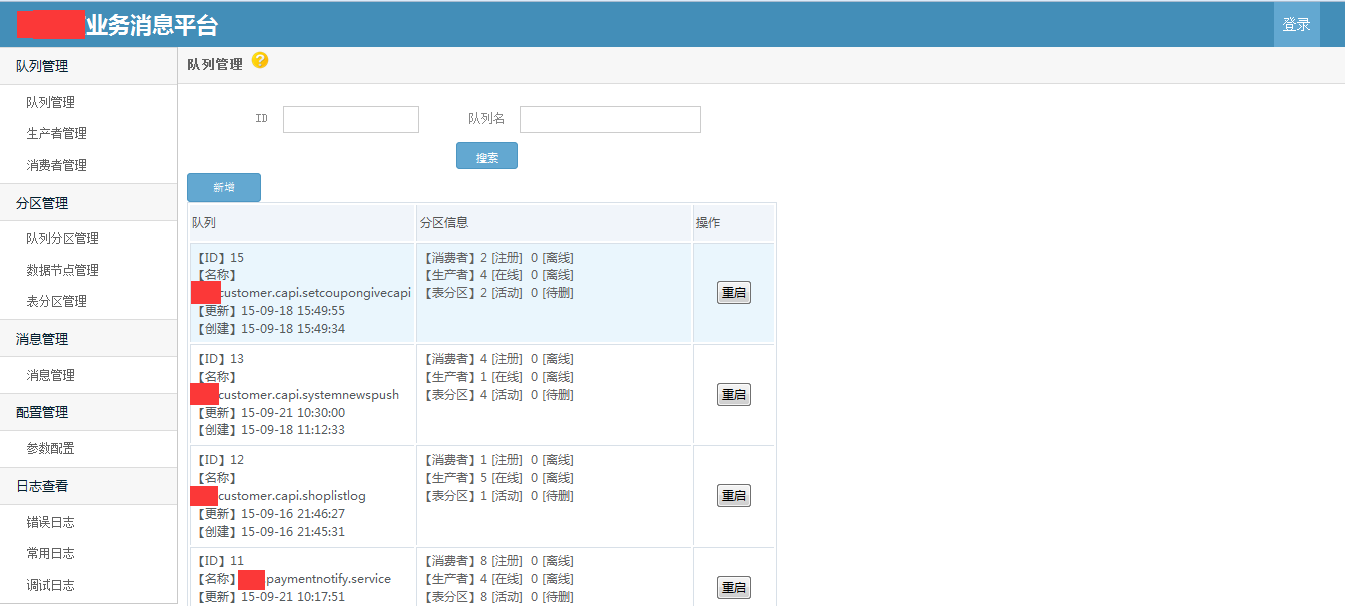 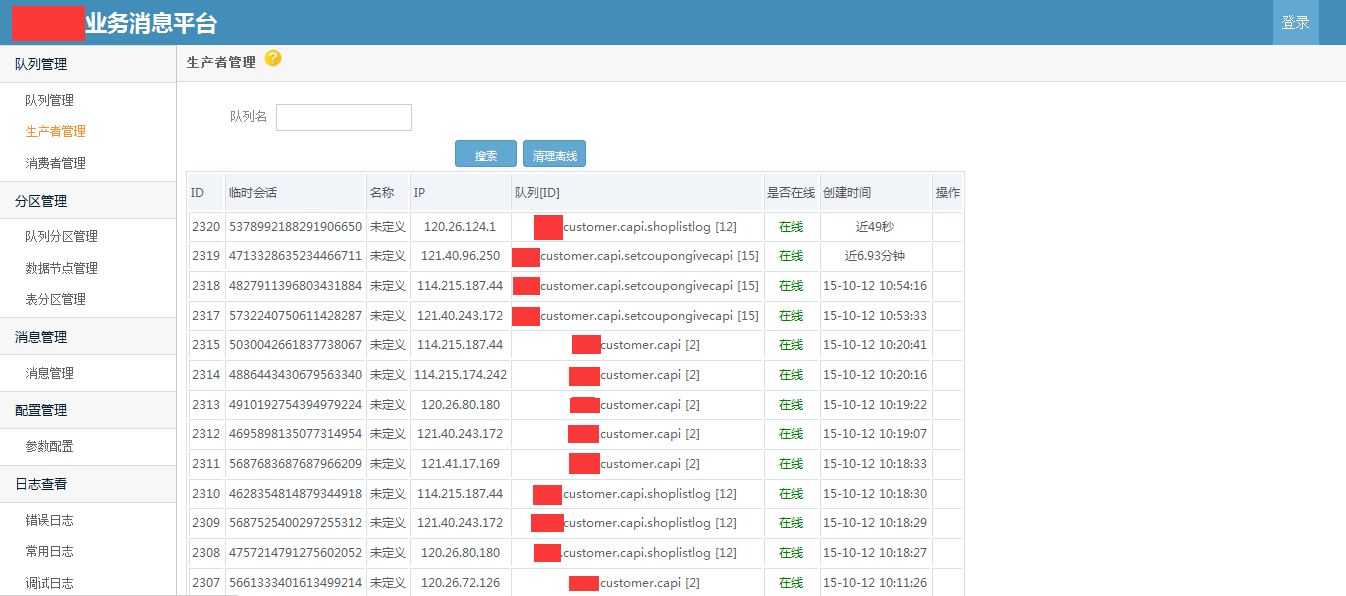 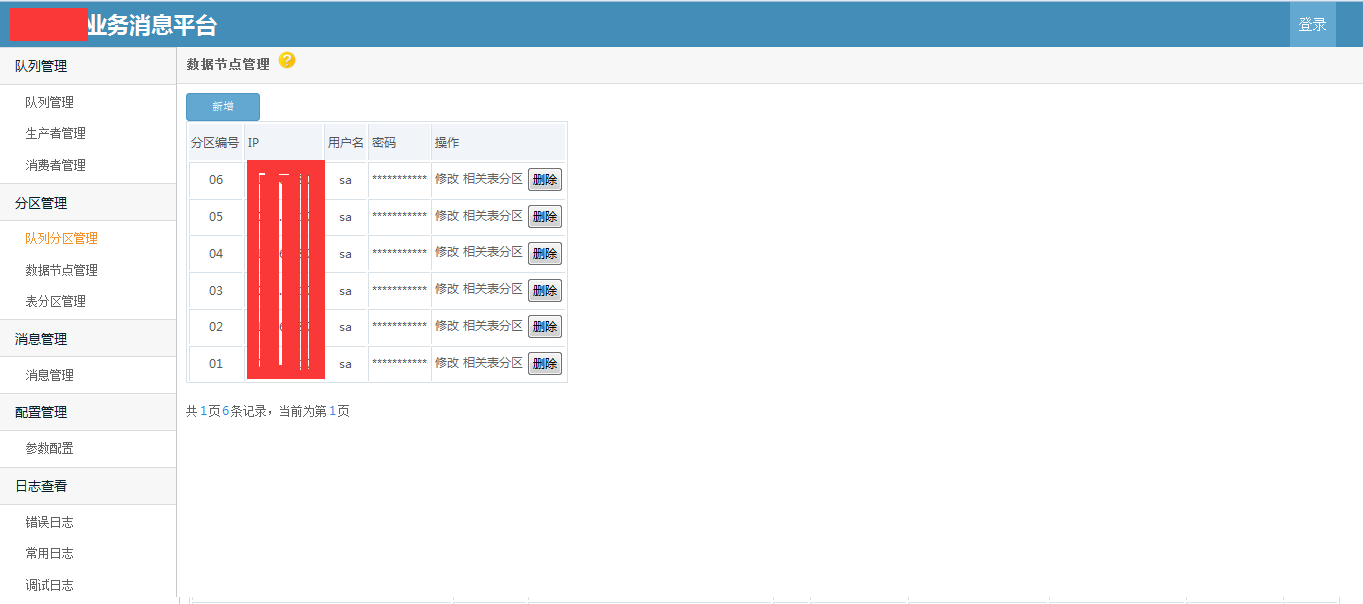  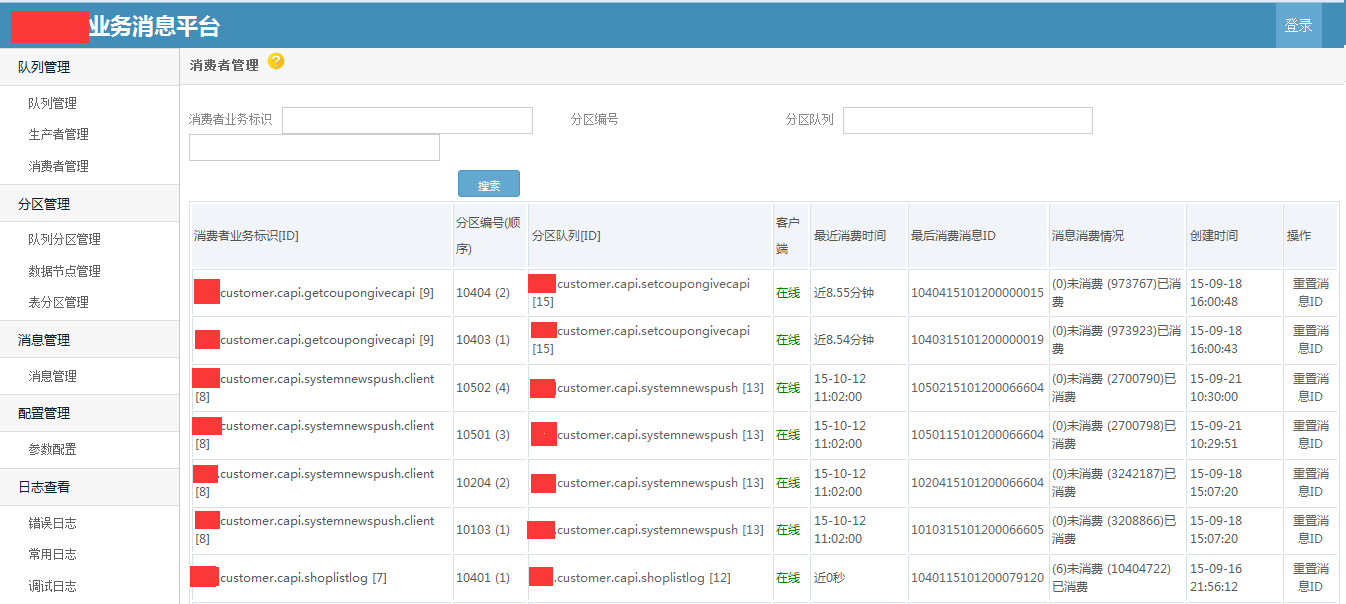 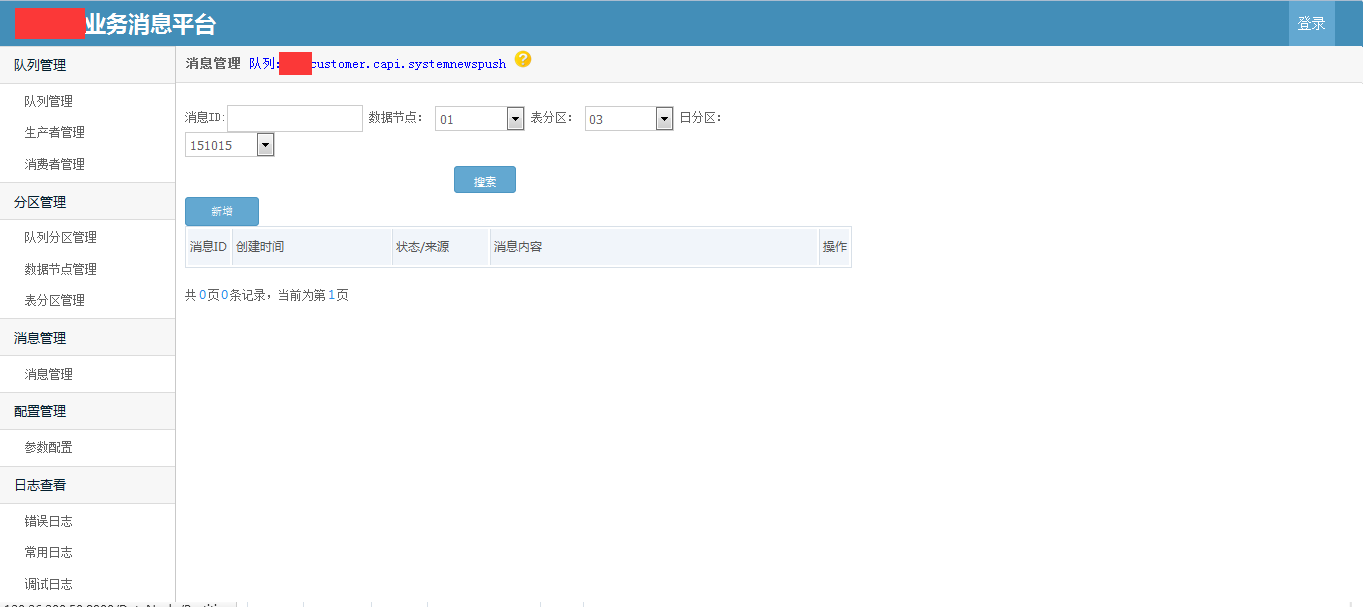 测试文档查看开源项目 “文档”目录 安装文档查看开源项目 “文档”目录 代码分析文档查看开源项目"文档"->"Business MQ实现分析-徐品.docx" ##.net 开源第三方开发学习路线 ## - 路线1:下载开源源码->学习开源项目->成功部署项目(根据开源文档或者QQ群项目管理员协助)->成为QQ群相关项目管理员->了解并解决日常开源项目问题->总结并整理开源项目文档并分享给大家或推广->成为git项目的开发者和参与者
- 路线2:下载开源源码->学习开源项目->成功部署项目(根据开源文档或者QQ群项目管理员协助)->在实际使用中发现bug并提交bug给项目相关管理员
- 路线3:下载开源源码->学习开源项目->成功部署项目(根据开源文档或者QQ群项目管理员协助)->自行建立开源项目分支->提交分支新功能给项目官方开发人员->官方开发人员根据项目情况合并新功能并发布新版本
关于.net 开源生态圈的构想.net 生态闭环:官方开源项目->第三方参与学习->第三方改进并提交新功能或bug->官方合并新功能或bug->官方发布新版本
为什么开源? .net 开源生态本身弱,而强大是你与我不断学习,点滴分享,相互协助,共同营造良好的.net生态环境。
开源理念: 开源是一种态度,分享是一种精神,学习仍需坚持,进步仍需努力,.net生态圈因你我更加美好。
作者:车江毅  |

 客服电话
客服电话
 APP下载
APP下载

 官方微信
官方微信











请发表评论